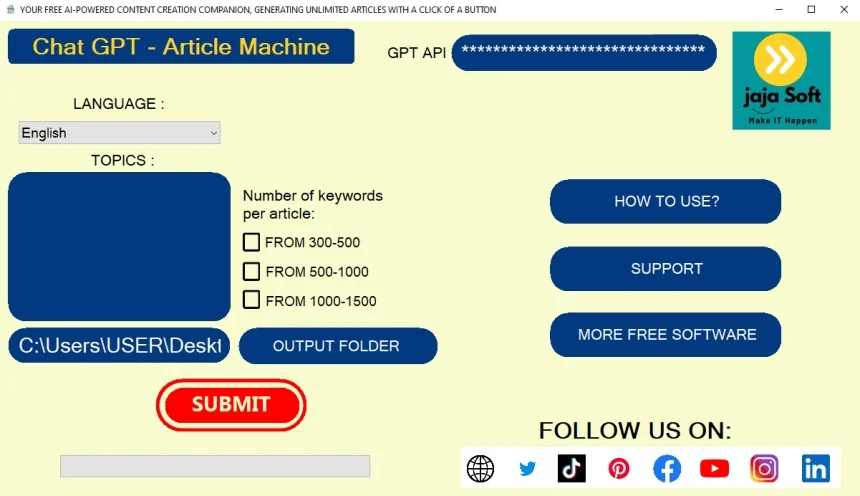
免费批量文章翻译器(任何语言!)仅适用于 Windows
免费批量文章翻译器,支持 任何语言之间的互译,操作简单高效,专为 Windows 系统 用户打造。可一次性翻译大量文章、文本或文档,支持多国语言自动识别,适合站长、写手、跨境电商卖家和外贸人员使用

免费批量文章翻译器,支持 任何语言之间的互译,操作简单高效,专为 Windows 系统 用户打造。可一次性翻译大量文章、文本或文档,支持多国语言自动识别,适合站长、写手、跨境电商卖家和外贸人员使用
如果您不想使用 GUI,这里是完整的代码:它建立在 python 之上,您只需要知道如何使用 python 并安装 nessecarry 要求。
============================================
从 deep_translator 导入 GoogleTranslator
导入线程
从并发.futures 导入 ThreadPoolExecutor,as_completed
导入时间
导入随机
从 pathlib 导入 Path
导入 os
def translate(text, source, target):
translator = GoogleTranslator() # 您必须为每个请求创建一个,否则多线程将失败,因为每个实例一次处理一个请求。
translator.source = 源
translator.target = 目标
return translator.translate(text)
def translate_and_save(source_path, save_path, source_lang, target_lang, max_chunk_length, num_workers):
try:
if not source_lang or not target_lang:
raise ValueError("请选择源语言和目标语言")
# 将文本行拆分成每行 5000 个字符的块
chunks = []
current_chunk = ""
with open(source_path, "r", encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
if len(current_chunk) + len(line) < max_chunk_length:
current_chunk += line
else:
chunks.append(current_chunk)
current_chunk = line
# 如果有,则附加剩余的块
if current_chunk:
chunks.append(current_chunk)
n_chunks = len(chunks) # 使用
多线程
ThreadPoolExecutor(max_workers=num_workers) as executor:
futures = [
executor.submit(
lambda text: translate(text, source_lang, target_lang),
chunk
) for chunk in chunks
]
for i, future in enumerate(as_completed(futures)):
# 更新进度条
print((i + 1) * 100 // n_chunks)
# 保存
translated_text = "\n".join([future.result() for future in futures])
with open(save_path, "w", encoding="utf-8") as f:
f.write(translated_text)
print("翻译完成")
except Exception as e:
print(e)
def start_translation(source_path,save_path,source_lang,target_lang):
#需要在worker中: =====
# source_path = input("输入文件夹路径: ")
# save_path = input("输出文件夹路径: ")
# source_lang = input("源语言代码(例如'en'): ")
# target_lang = input("目标语言代码(例如'fr'): ")
max_chunk_length = 5000
# 如果输出文件夹不存在,则创建它
Path(save_path).mkdir(parents=True, exist_ok=True)
# 遍历输入文件夹中的文件
for filename in os.listdir(source_path):
if filename.endswith('.txt'):
input_file_path = os.path.join(source_path, filename) # 输入文件的完整路径
output_file_path = os.path.join(save_path, f"translated_{filename}") #输出文件的完整路径
num_workers = 4
translate_and_save(input_file_path, output_file_path, source_lang, target_lang, max_chunk_length, num_workers)
print(f"{filename} is transformed successful")
tmemail = random.randint(10,15)
time.sleep(tmemail)
def start_translation_thread():
new_thread = threading.Thread(target=start_translation)
new_thread.start()
new_thread.join()
下载地址
https://down.scripthub.cc/drive/s/WgvVkiuINq6G4UngAqlSBODx085643
分享
你的反应是什么?
 喜欢
0
喜欢
0
 不喜欢
0
不喜欢
0
 爱
0
爱
0
 有趣的
0
有趣的
0
 生气的
0
生气的
0
 伤心
0
伤心
0
 哇
0
哇
0